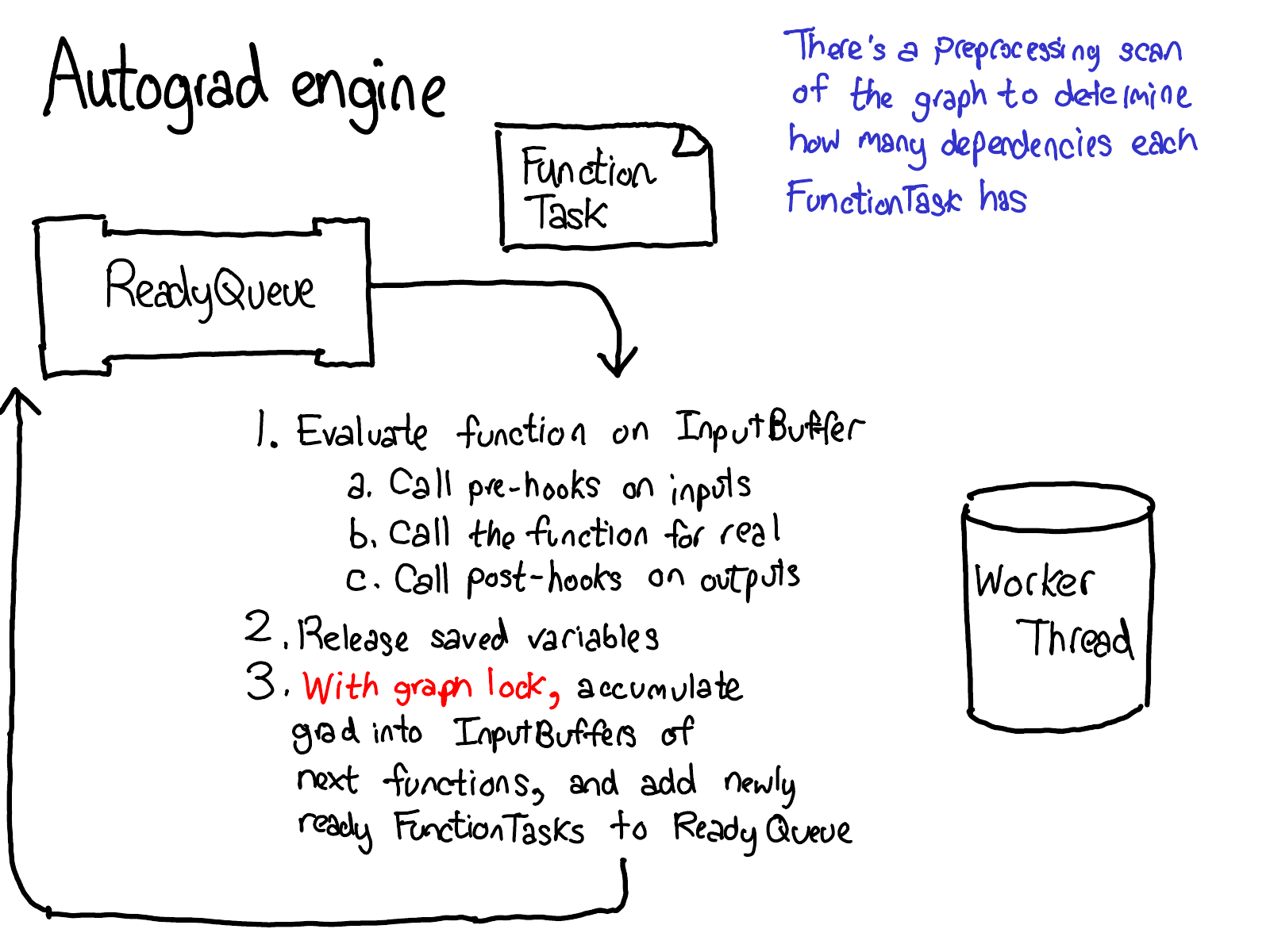
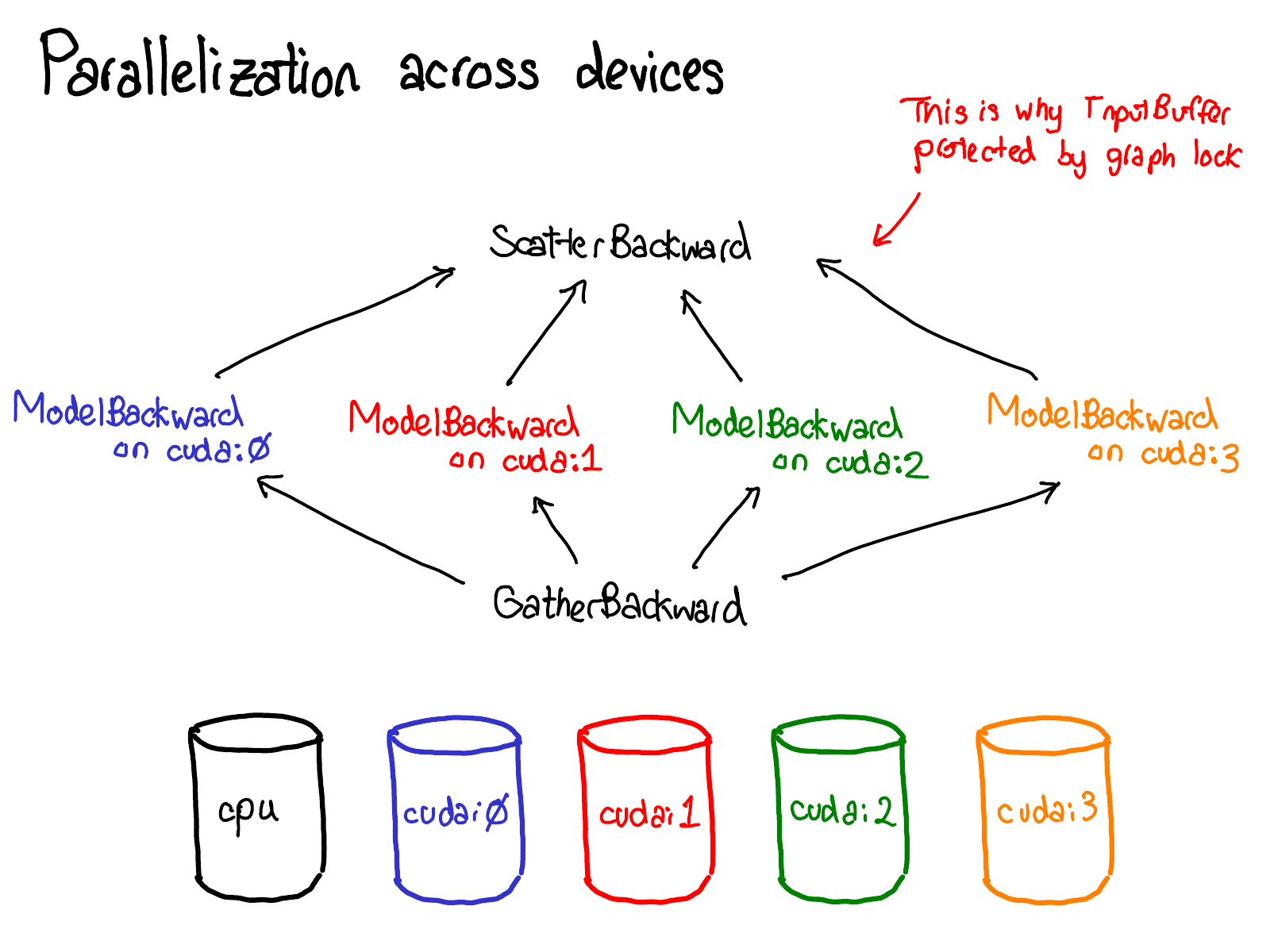
Autograd 内部机制#
参考:PyTorch 内部机制
PyTorch 最引人注目的特点是在张量上提供自动求导功能(现在还有其他酷炫的功能,比如 TorchScript!)
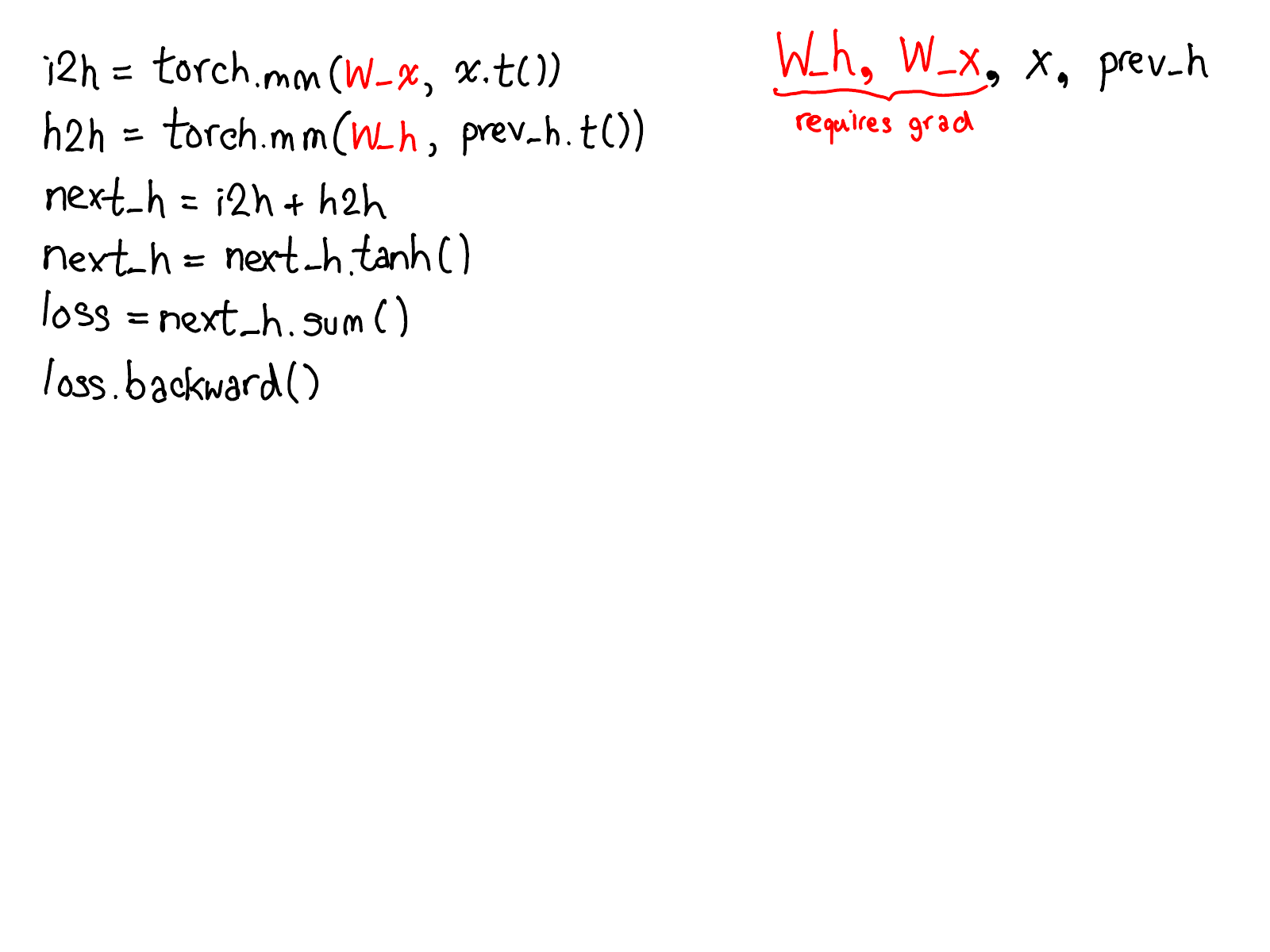
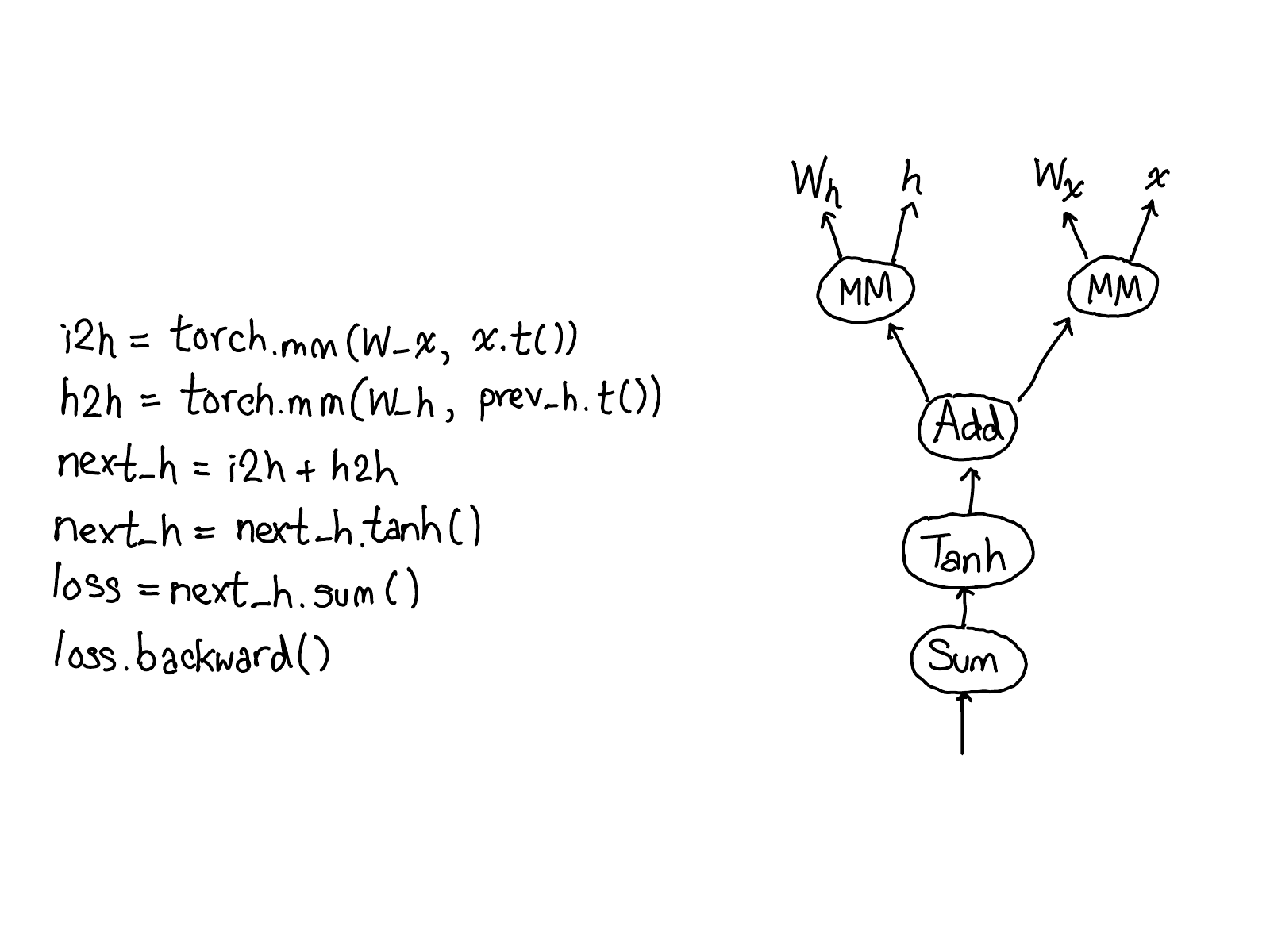
…并填写实际计算网络梯度的缺失代码:

花一点时间研究这张图表。有很多内容需要理解;这里是你应该关注的:
首先,请将注意力集中在红色和蓝色的变量上。PyTorch 实现了反向模式自动微分,这意味着实际上是从前向计算的“反向”路径来计算梯度的。如果你查看变量名称,你会发现,在红色部分的底部,计算的是
loss;然后,在蓝色部分程序的第一步,计算的是grad_loss。loss是从next_h2计算得到的,所以计算grad_next_h2。技术上,称之为grad_的变量实际上并不是梯度;它们实际上是左乘了向量的雅可比矩阵,但在 PyTorch 中直接称之为grad,大多数人都知道指的是什么。如果代码的结构保持不变,其行为会有所不同:每一步从前向计算都会被替换为不同的计算,这个计算代表了前向运算的导数。例如,
tanh算子被翻译成tanh_backward算子(这两个步骤在图的左侧通过一条灰色的线连接)。前向算子和反向算子的输入和输出是交换的:如果前向算子产生了next_h2,那么反向算子会将grad_next_h2作为输入。
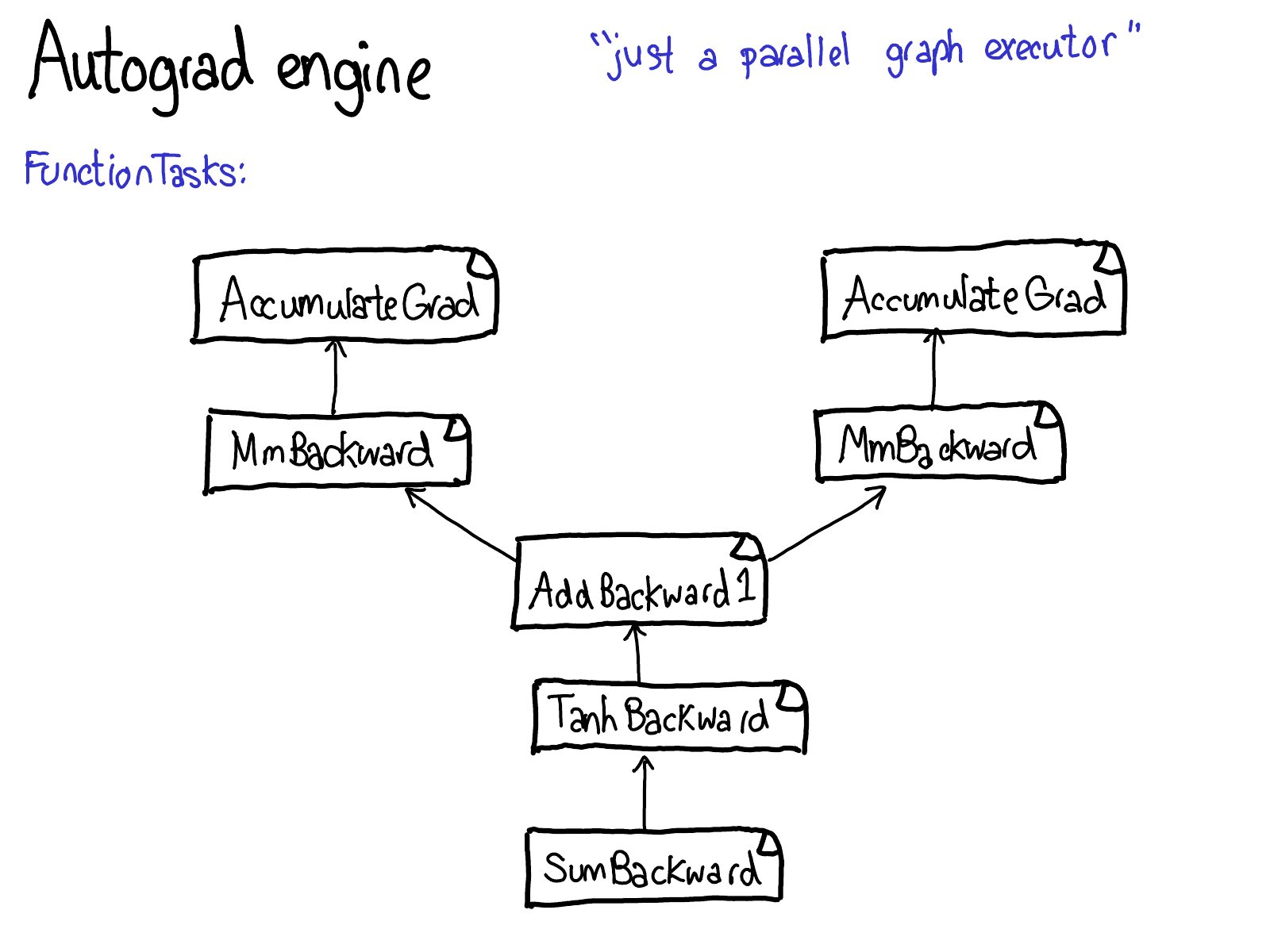
自动求导的整个目的就是执行由这张图描述的计算,但从未实际生成这段源代码。PyTorch 的自动求导并不进行源代码到源代码的转换(尽管 PyTorch JIT 知道如何进行符号微分)。
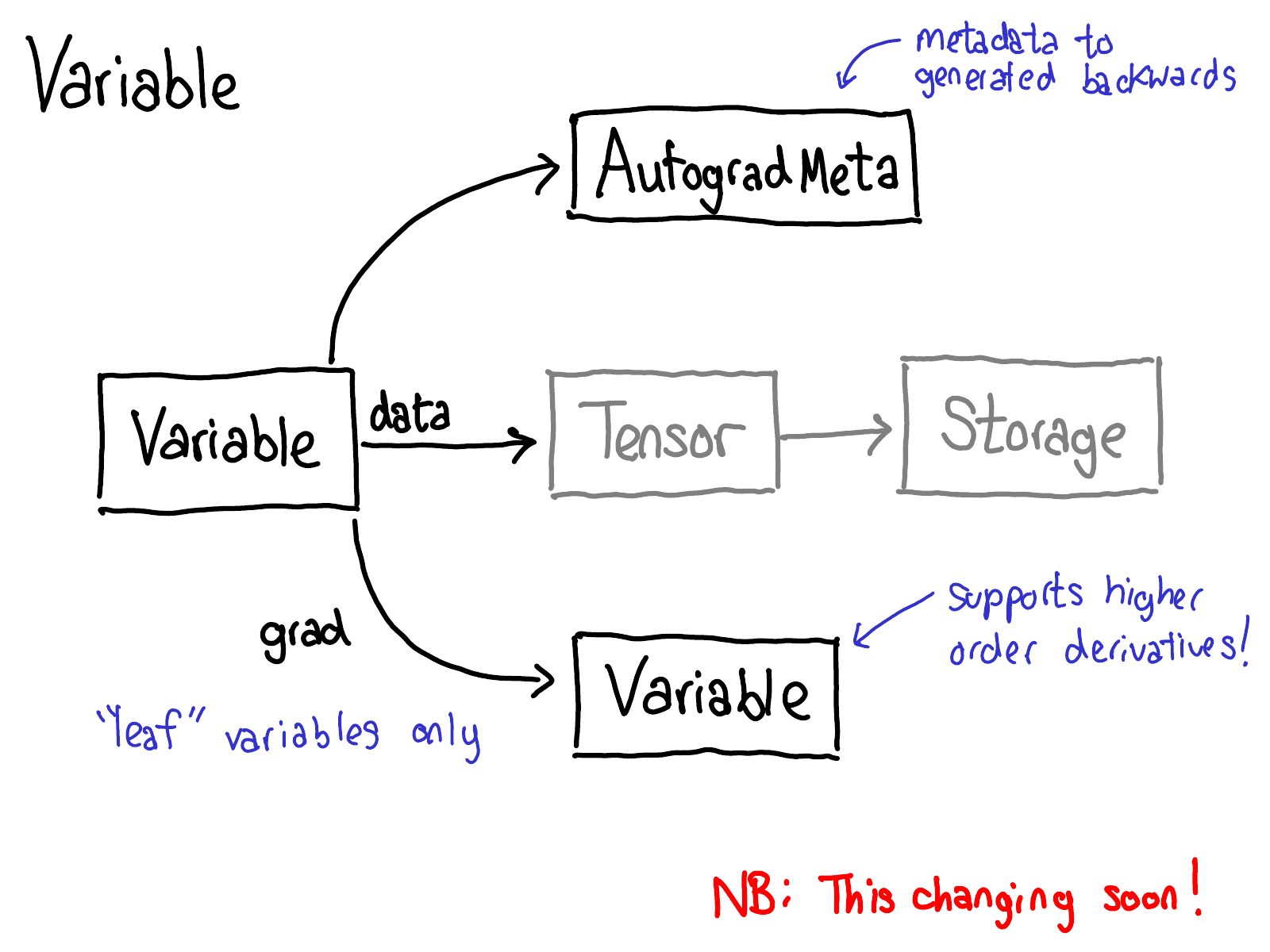
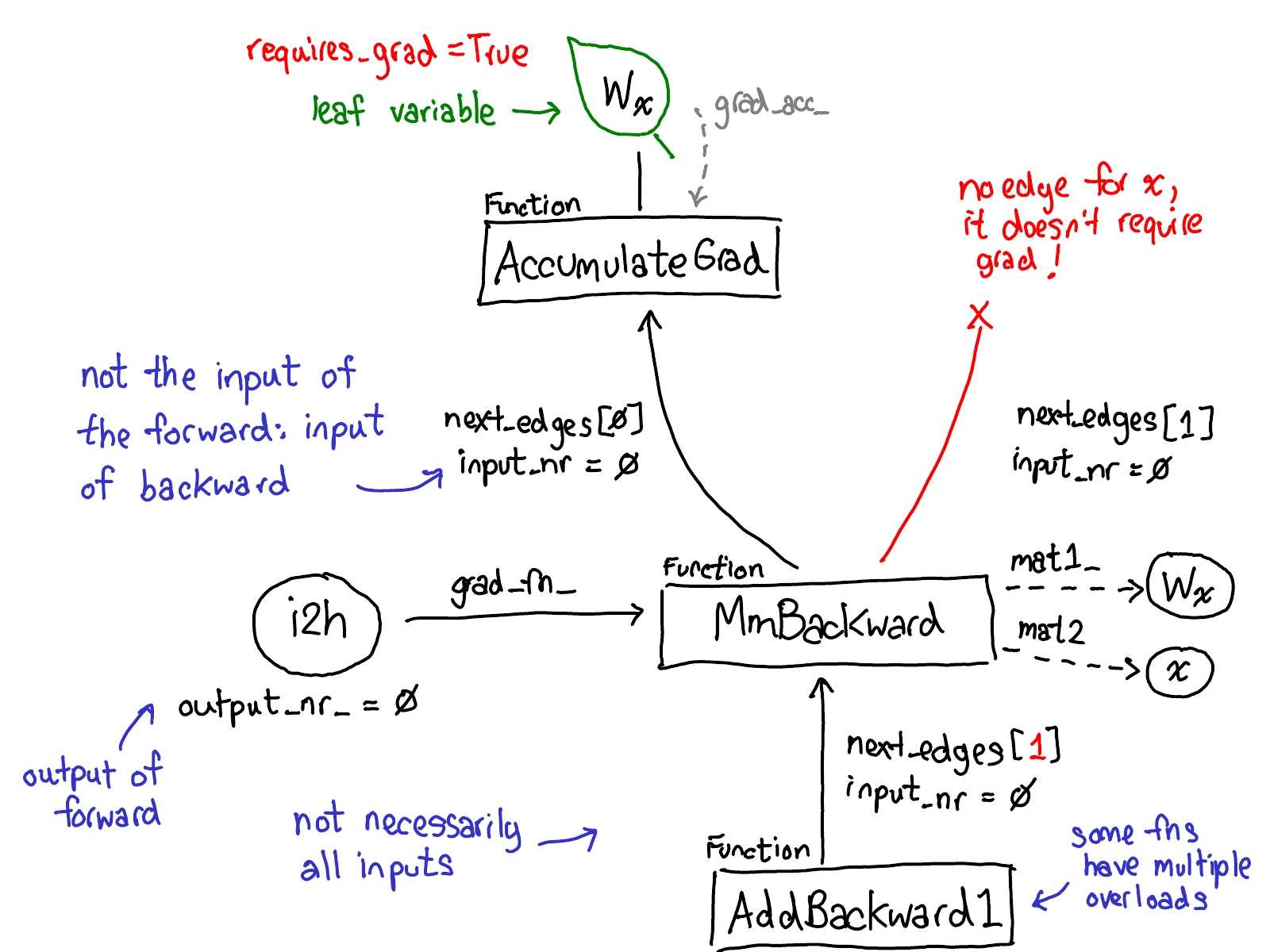
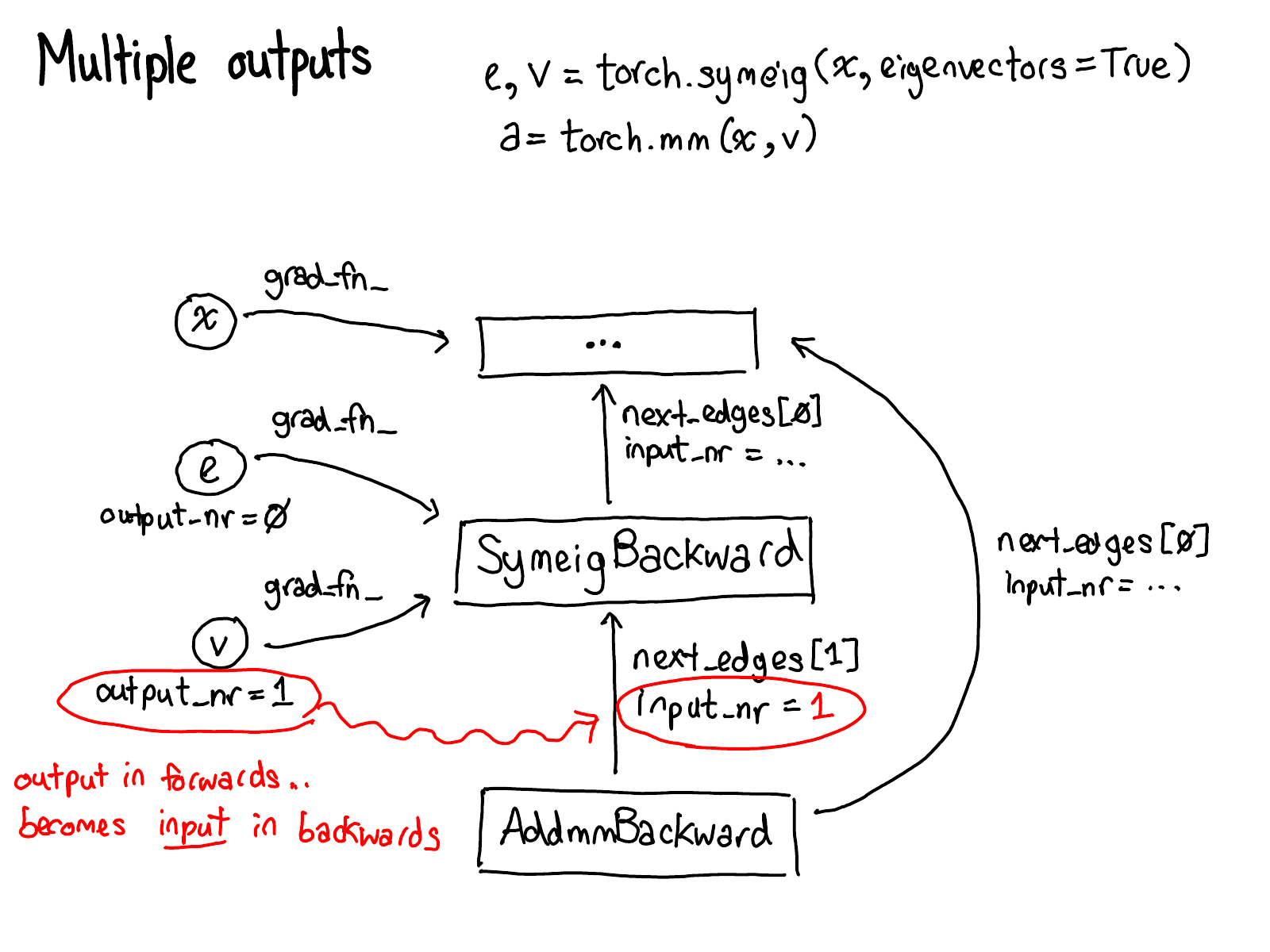
为了做到这一点,在对张量进行操作时需要存储更多的元数据。调整一下对张量数据结构的看法:现在不仅有指向存储的张量,还有一种变量包装了这个张量,并且存储了更多用于执行自动求导的信息(AutogradMeta),当用户在 PyTorch 脚本中调用 loss.backward() 时,这些信息就派上了用场。
还需要更新关于分发机制的认识:
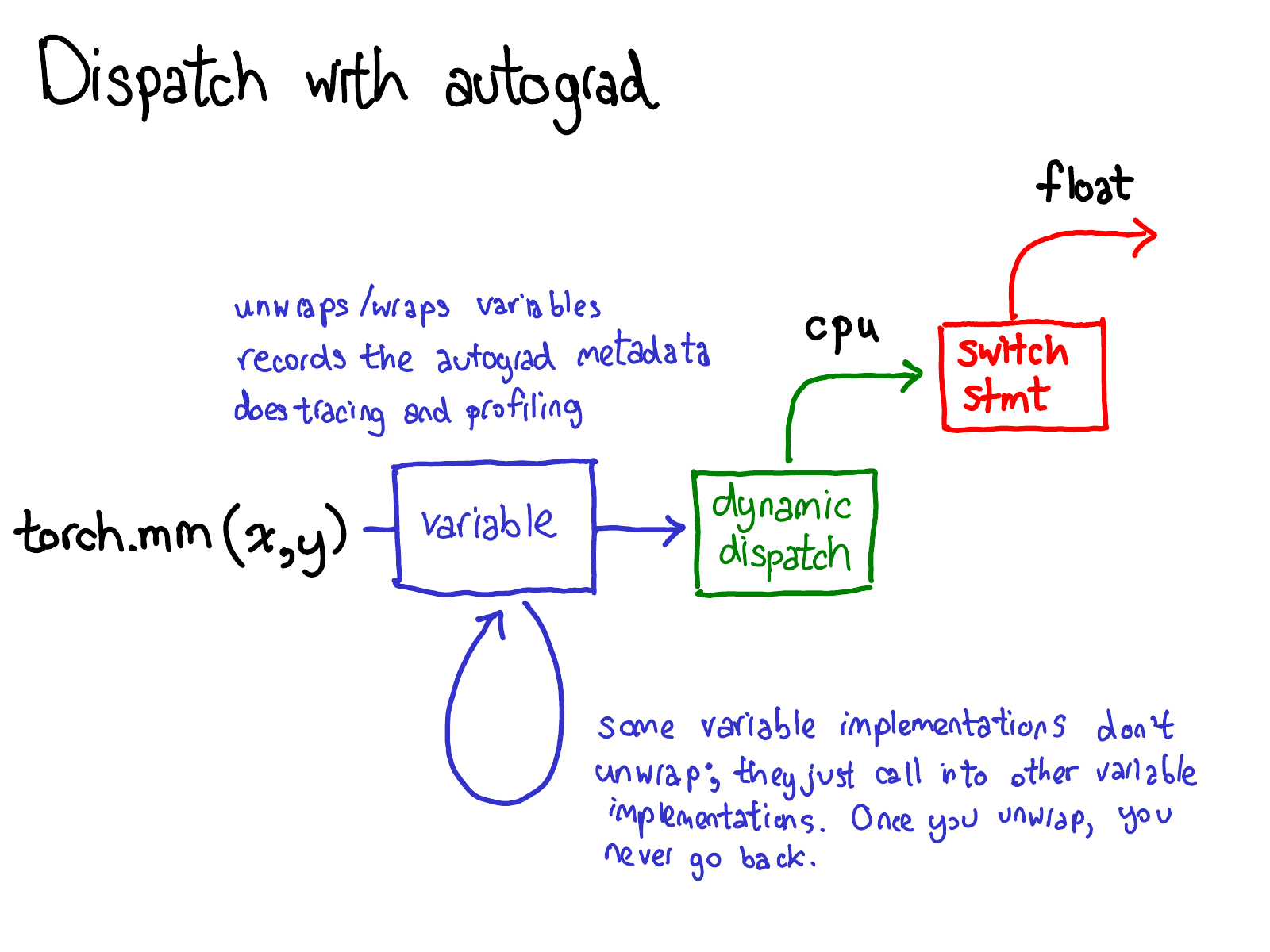
在将任务分派给 CPU 或 CUDA 实现之前,还会有针对变量的分派,这个分派负责解包变量,调用底层实现(绿色部分),然后将结果重新封装成变量,并记录必要的自动求导元数据以用于反向传播。
有些实现不会解包,而是直接调用其他变量的实现。因此,你可能会在 Variable 的世界里待上一阵子。然而,一旦你解包并进入非 Variable 的 Tensor 世界,那就结束了;你不会再回到 Variable 世界(除非从你的函数返回)。