张量内部机制#
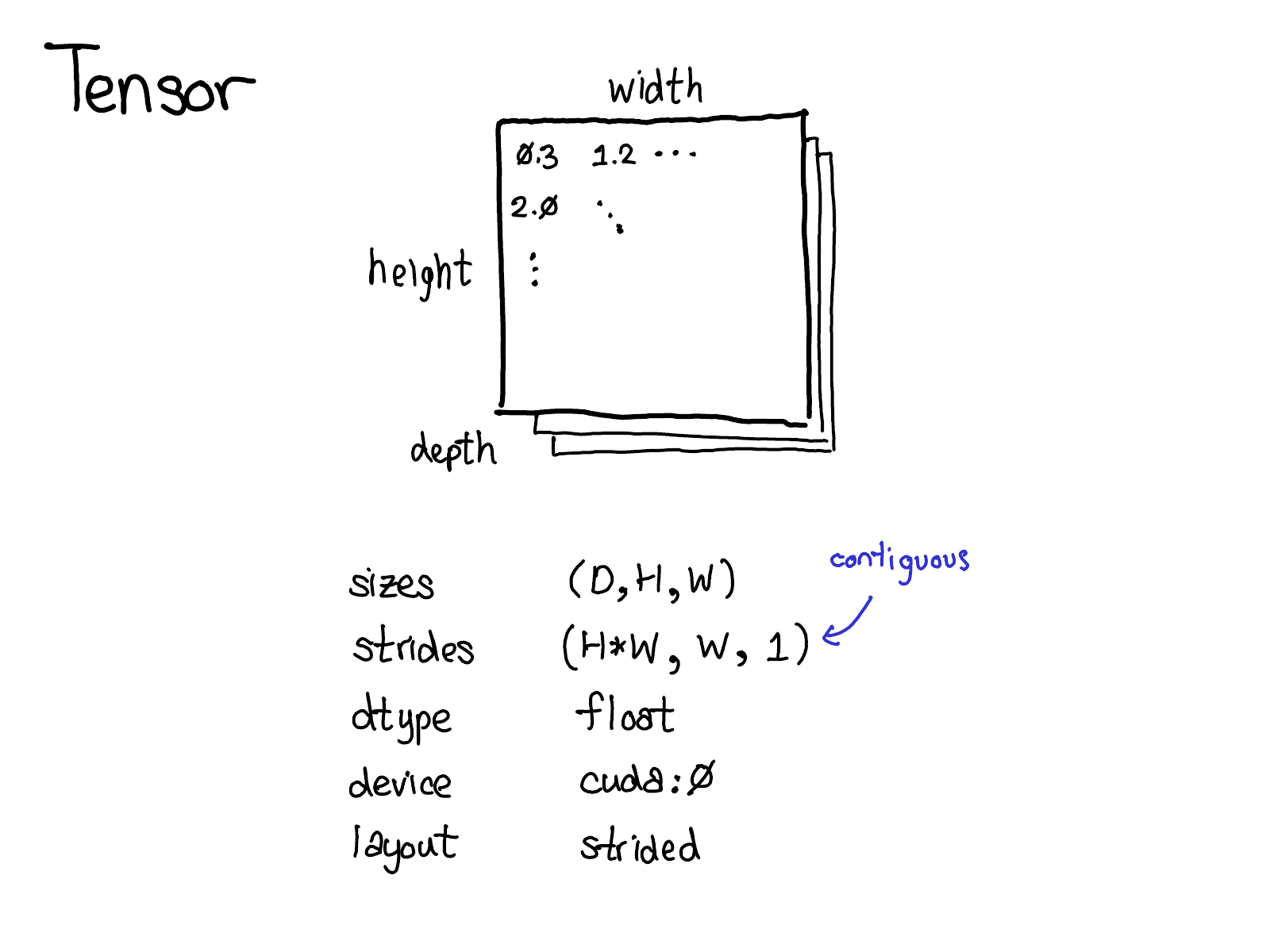
张量是 PyTorch 中的核心数据结构。你可能对张量直观地代表什么已经有了一定的了解:它是包含某种标量类型的 \(n\) 维数据结构,比如浮点数、整数等。可以将张量视为包含一些数据,以及描述张量大小、元素类型(dtype)和张量所在的设备(CPU 内存?CUDA 内存?)的一些元数据。
步长#
还有一项你可能不太熟悉的元数据:步长。步长实际上是 PyTorch 的特色功能,因此值得详细讨论一下。
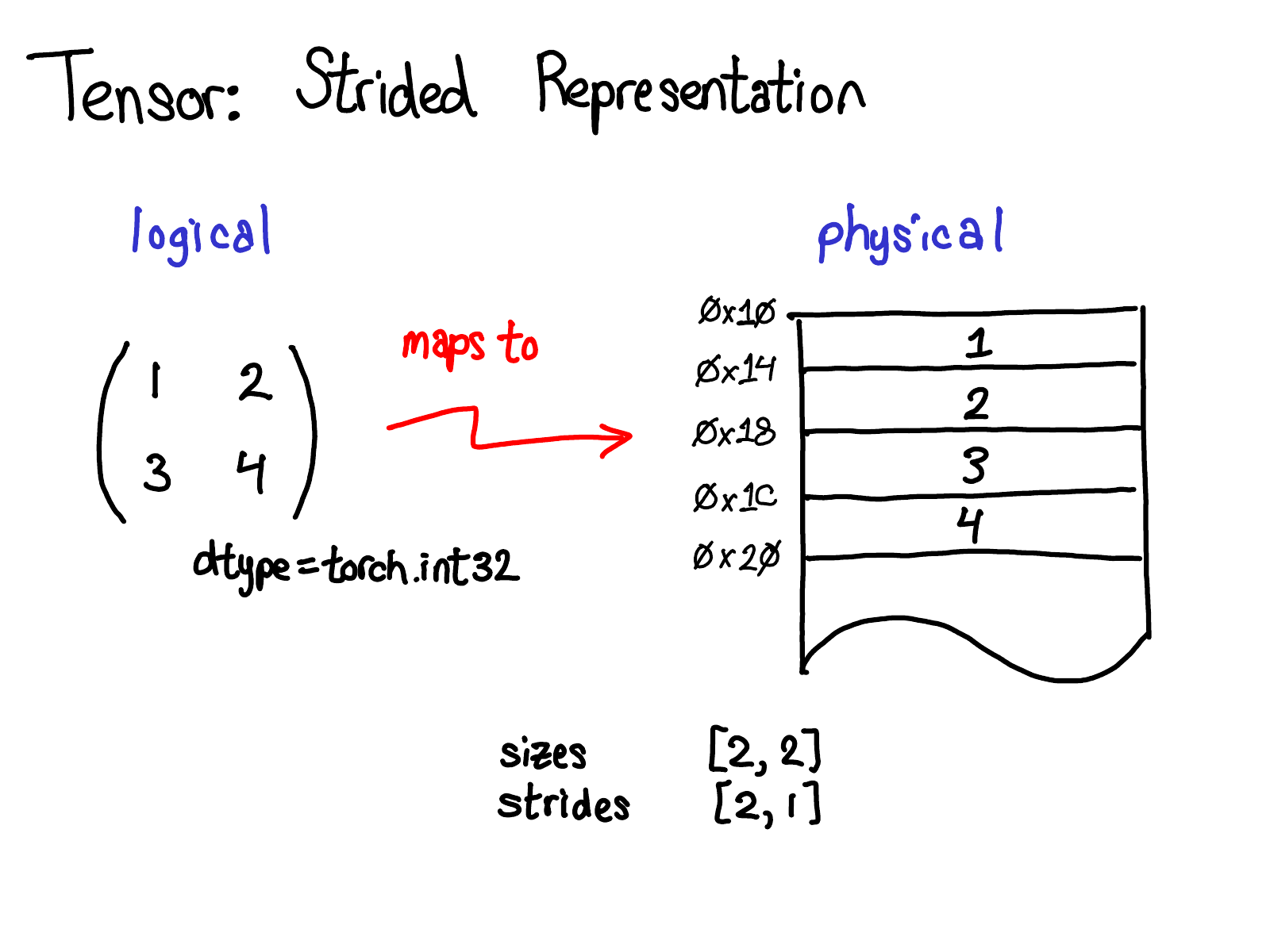
张量是数学概念。但在计算机中表示张量时,要为其定义某种物理表示形式。最常见的表示方法是将张量中的每个元素连续地存储在内存中(这就是术语“连续”(contiguous)的来源),逐行将每个元素写入内存,如上图所示。在上述示例中,指定了张量包含 32 位整数,因此可以看到每个整数占据一个物理地址,每个地址之间相差四个字节。为了记住张量的实际维度,还需要记录下这些尺寸作为额外的元数据。
那么,步长和这张图有什么关系呢?
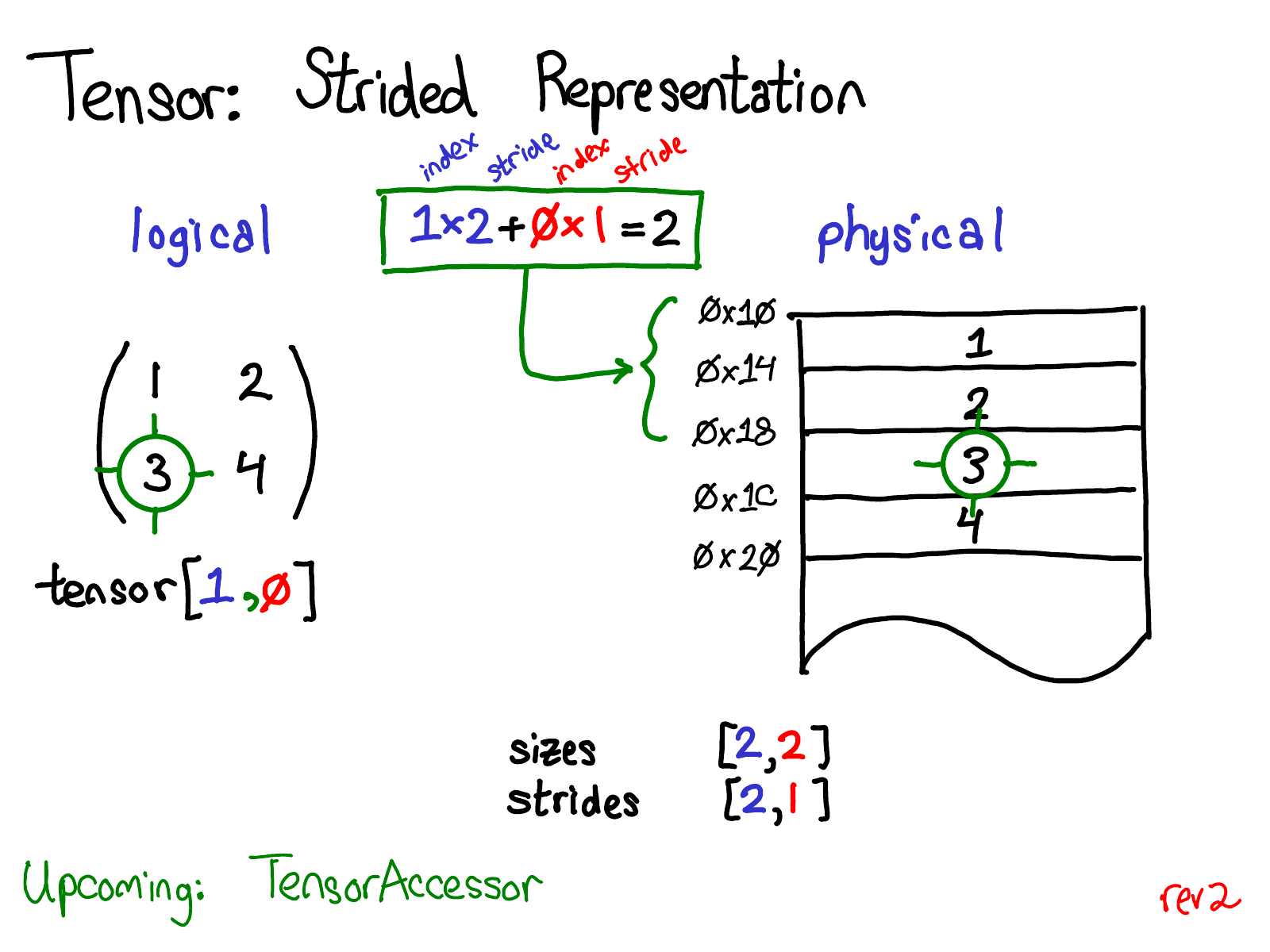
假设想访问逻辑表示中的 tensor[1, 0] 位置的元素,如何将这个逻辑位置转换为物理内存中的位置?步长告知了如何做到这一点:要找出张量中任何元素的位置,需要将每个索引与该维度对应的步长相乘,然后将它们相加。在上面的图片中,将第一个维度着色为蓝色,第二个维度着色为红色,这样你可以跟踪索引和步长的计算过程。进行这个求和运算后,得到的结果是两个(基于零索引),确实,数字 3 位于连续数组的起始位置下方两个位置。
备注
TensorAccessor 类,用于处理索引计算。当你使用 TensorAccessor 而不是原始指针时,这些计算会在后台为你处理。
步长是向 PyTorch 用户提供视图的基础。例如,假设想提取出张量,表示上述张量的第二行:
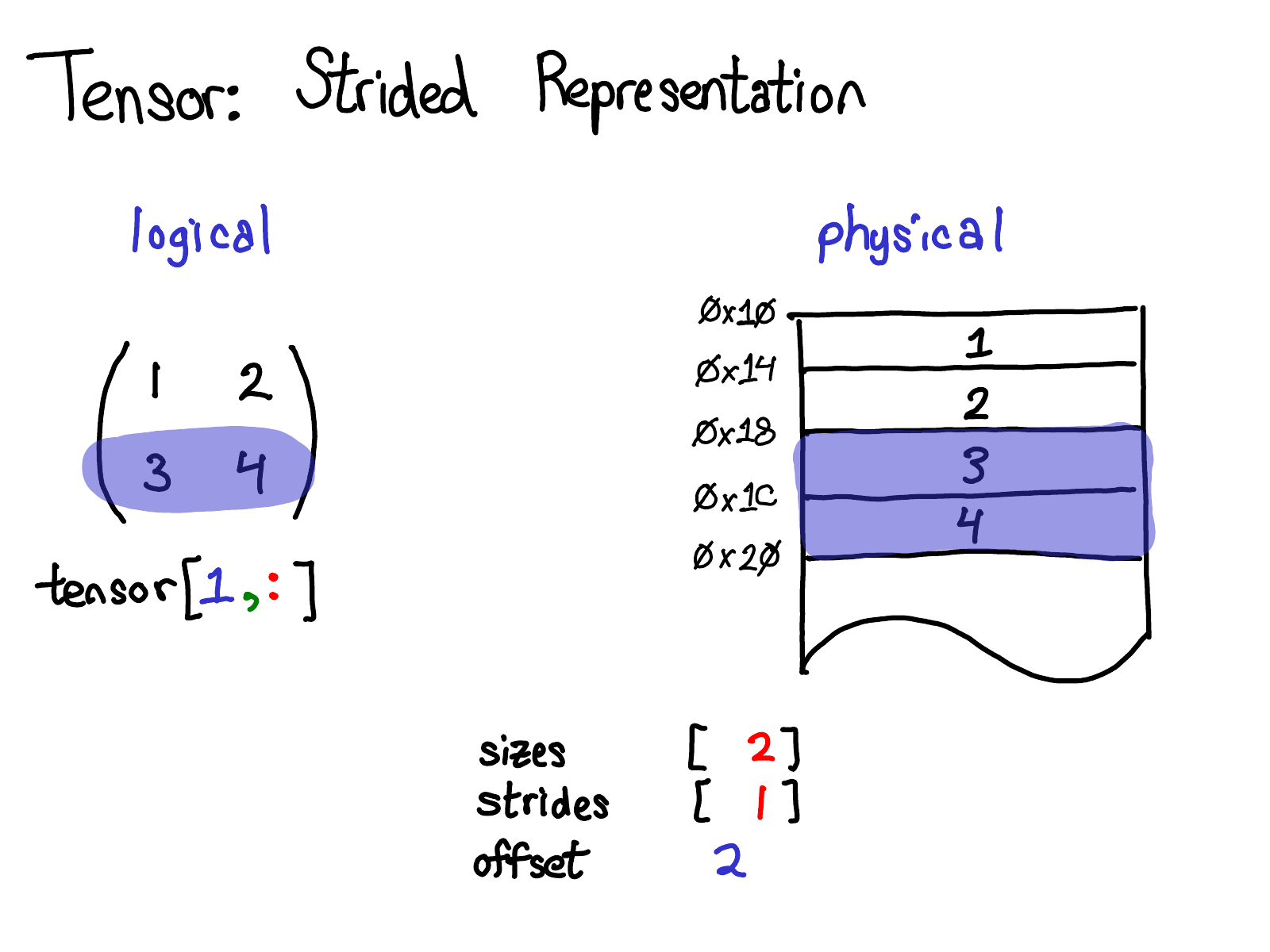
使用高级索引支持,只需输入 tensor[1, :] 即可获取此行。重点在于:执行此操作时,并没有创建新的张量;相反,只是返回基于底层数据的不同视图的张量。这意味着,例如,如果在该视图中编辑数据,它将反映在原始张量中。在这种情况下,不难看出如何做到这一点:three 和 four 位于连续的内存中,需要做的就是记录偏移量,表示这个(逻辑)张量的数据位于从顶部向下两个的位置。(每个张量都会记录偏移量,但大多数情况下它是零,在这种情况下,会在图表中省略它。)
更有趣的情况是,如果想取第一列:
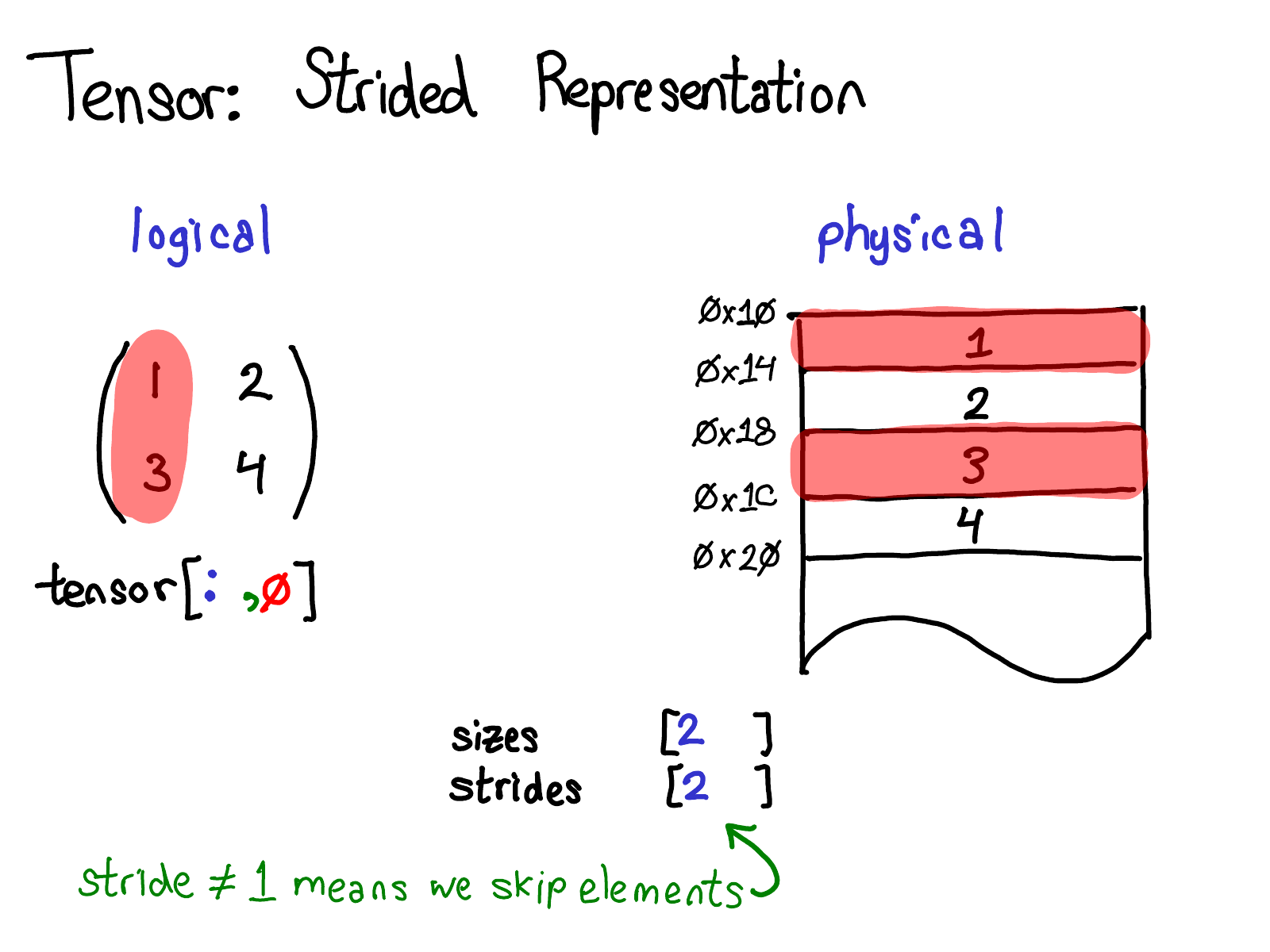
当查看物理内存时,可以看到列中的元素并不是连续的:每个元素之间有一个空隙。这时,步长就派上用场了:不再指定步长为 1,而是指定步长为 2,表示从一个元素到下一个元素之间需要跳过两个位置。(顺便提一句,这就是为什么叫“步长”的原因:如果把索引看作在布局上行走,步长就表示每次迈一步时向前走多少个位置。)
stride 表示法实际上可以让你以各种有趣的方式对张量进行视图操作;如果你想探索这些可能性,可以试试 Stride 可视化工具。
暂时退一步,思考如何实现这种功能(毕竟,这是一次内部机制讨论。)如果可以对张量进行视图操作,这就意味着必须将张量的概念(用户可见的概念,你所熟知和喜爱的概念)与实际存储张量数据的物理数据(称为存储(storage))分离开来:
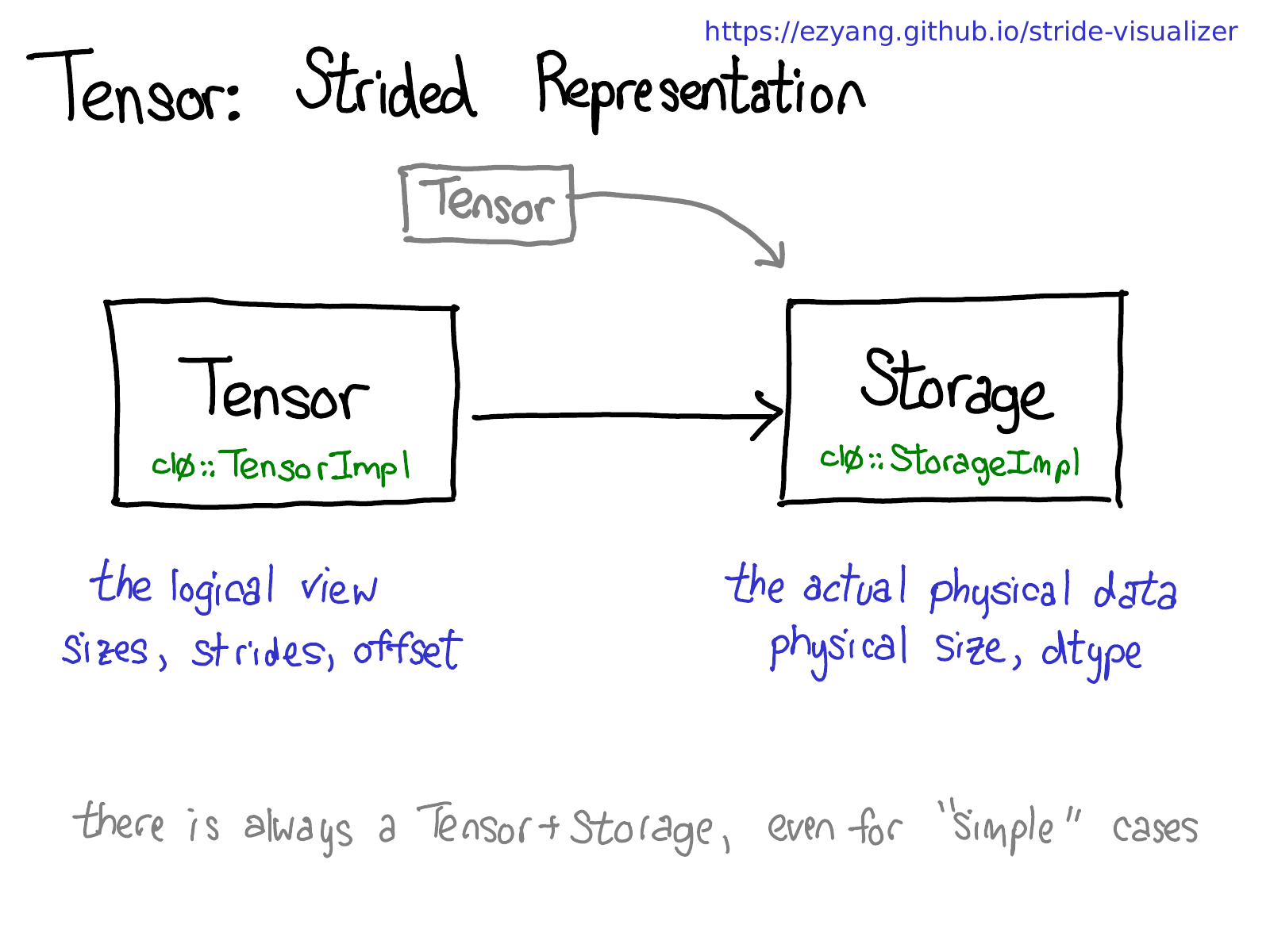
多个张量可能共享相同的存储。存储定义了张量的数据类型和物理大小,而每个张量记录自己的尺寸、步长和偏移量,定义了物理内存的逻辑含义。
要意识到,即使是那些不需要存储的情况(例如,只是分配了连续的张量 torch.zeros(2, 2) ),也总是会有一对 Tensor-Storage。
备注
顺便说一下,希望让这个图景不再成立;而不是有独立的存储概念,而是将视图定义为由 base tensor 支持的张量。这样做虽然稍微复杂一些,但好处是可以直接表示连续张量,而不需要通过存储进行间接访问。这样的改变会让 PyTorch 的内部表示更接近 NumPy 的表示。
张量的算子如何计算?#
已经讨论了很多关于张量的数据布局(有人可能会说,如果你的数据表示正确,其他一切都顺理成章)。但也很有必要简要谈谈张量上的算子是如何实现的。在最抽象的层面上,当你调用 torch.mm 时,会发生两次分发:
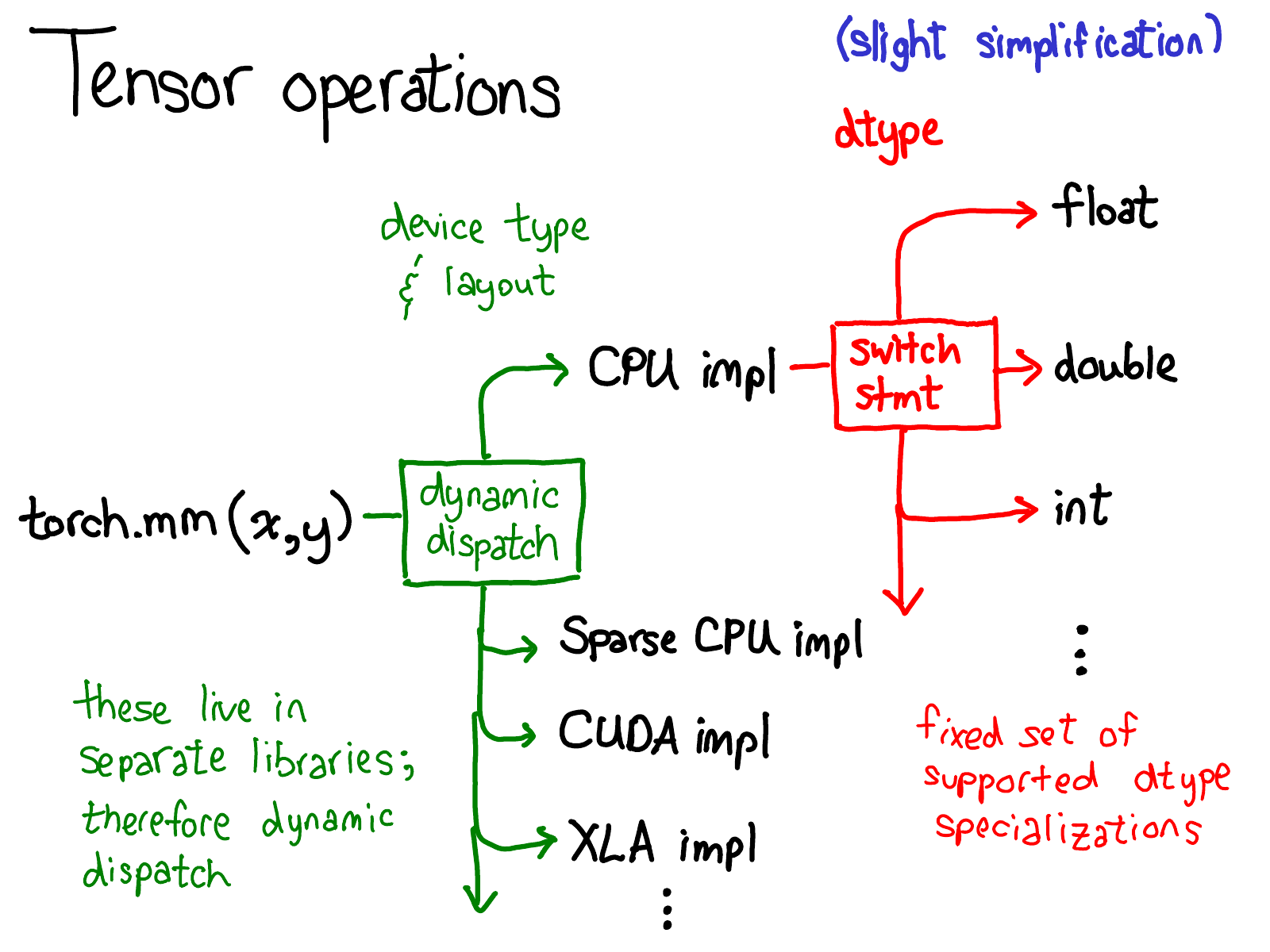
第一个分发基于张量的设备类型和布局:例如,它是 CPU 张量还是 CUDA 张量(同时,它是否是带步长张量或稀疏张量)。这是动态分发的:这涉及到虚函数调用。这很有道理,因为你需要在这里进行调度:CPU 矩阵乘法的实现与 CUDA 实现大不相同。这是动态分发的,因为这些内核可能存在于不同的库中(例如, libcaffe2.so 与 libcaffe2_gpu.so),因此你别无选择:如果你想进入你没有直接依赖的库,你就必须通过动态分发来实现这一点。
第二个分发是针对目标数据类型的数据类型分发。这个分发只是简单的开关语句,用于支持内核选择支持的所有数据类型。经过反思,这里确实需要一个分发:在 float 上实现乘法的 CPU 代码(或 CUDA 代码)与 int 上的代码不同。因此,需要为每种数据类型分别编写内核。
这可能是你理解 PyTorch 中算子调用方式时最重要的心理图像。当需要更详细地查看代码时,还会回到这张图。

张量扩展#
既然已经谈论了张量,也想花一点时间来探讨张量扩展的世界。毕竟,生活不仅仅是由密集的 CPU 浮点张量构成的。各种有趣的扩展正在发生,比如 XLA 张量、量化张量或 MKL-DNN 张量。作为张量库,需要考虑如何容纳这些扩展。
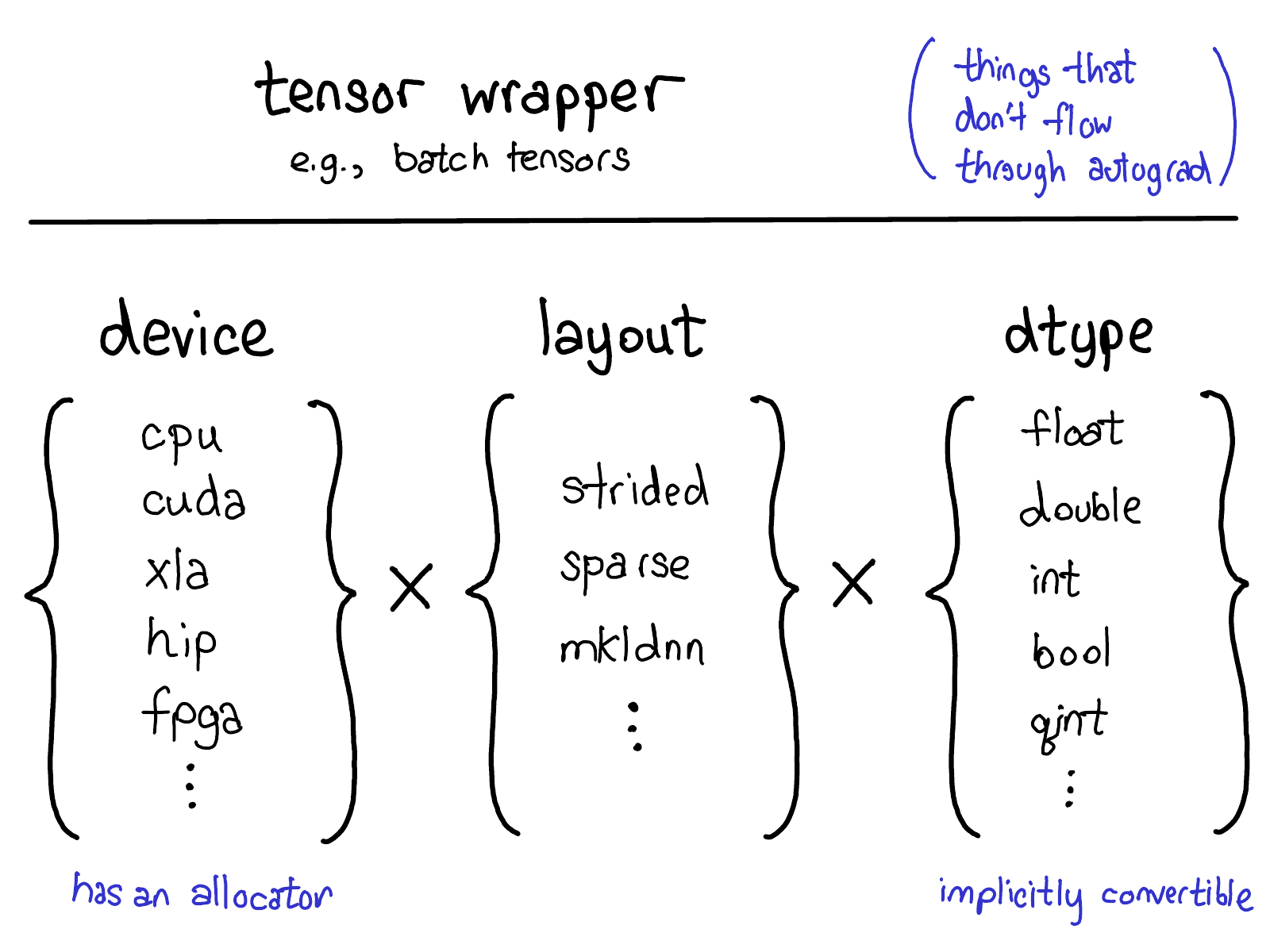
当前的扩展模型为张量提供了四个扩展点。首先,有三个参数的三位一体,它们唯一确定了张量的性质:
设备(device),即张量实际物理内存存储的位置,例如在 CPU 上、NVIDIA GPU(cuda)上,或者可能是 AMD GPU(hip)或 TPU(xla)上。设备的显著特点是它有自己的分配器,这个分配器不与其他设备共用。
布局(layout),描述了如何逻辑地解释这块物理内存。最常见的布局是张量的步进布局(strided tensor),但稀疏张量的布局则涉及一对张量,一个用于索引,一个用于数据;MKL-DNN 张量可能具有更加奇特的布局,比如块布局,这种布局不能仅通过 strides 来表示。
数据类型(dtype),描述了张量中每个元素实际存储的内容。这可以是浮点数或整数,也可以是例如量化的整数。
如果你想为 PyTorch 张量添加扩展,你应该考虑你会扩展哪些参数。这些参数的笛卡尔积定义了所有可能的张量。现在,并非所有这些组合都可能有内核(谁会为 FPGA 上的稀疏量化张量编写内核?),但在原则上,这种组合是有意义的,因此至少支持表达它。
还有一种方式可以扩展张量的功能,那就是围绕 PyTorch 张量编写包装类,并实现你的对象类型。这听起来可能很显而易见,但有时人们在应该编写包装类的情况下,却选择了扩展其中一个参数。包装类的显著优点是它们可以在树外完全开发。
你应该编写张量包装器,还是直接扩展 PyTorch 本身?关键测试是你是否需要在自动求导的反向传播过程中传递这个张量。例如,这个测试告诉我们稀疏张量应该是真正的张量扩展,而不仅仅是包含索引和值的 Python 对象:在涉及嵌入的网络优化中,希望由嵌入生成的梯度是稀疏的。
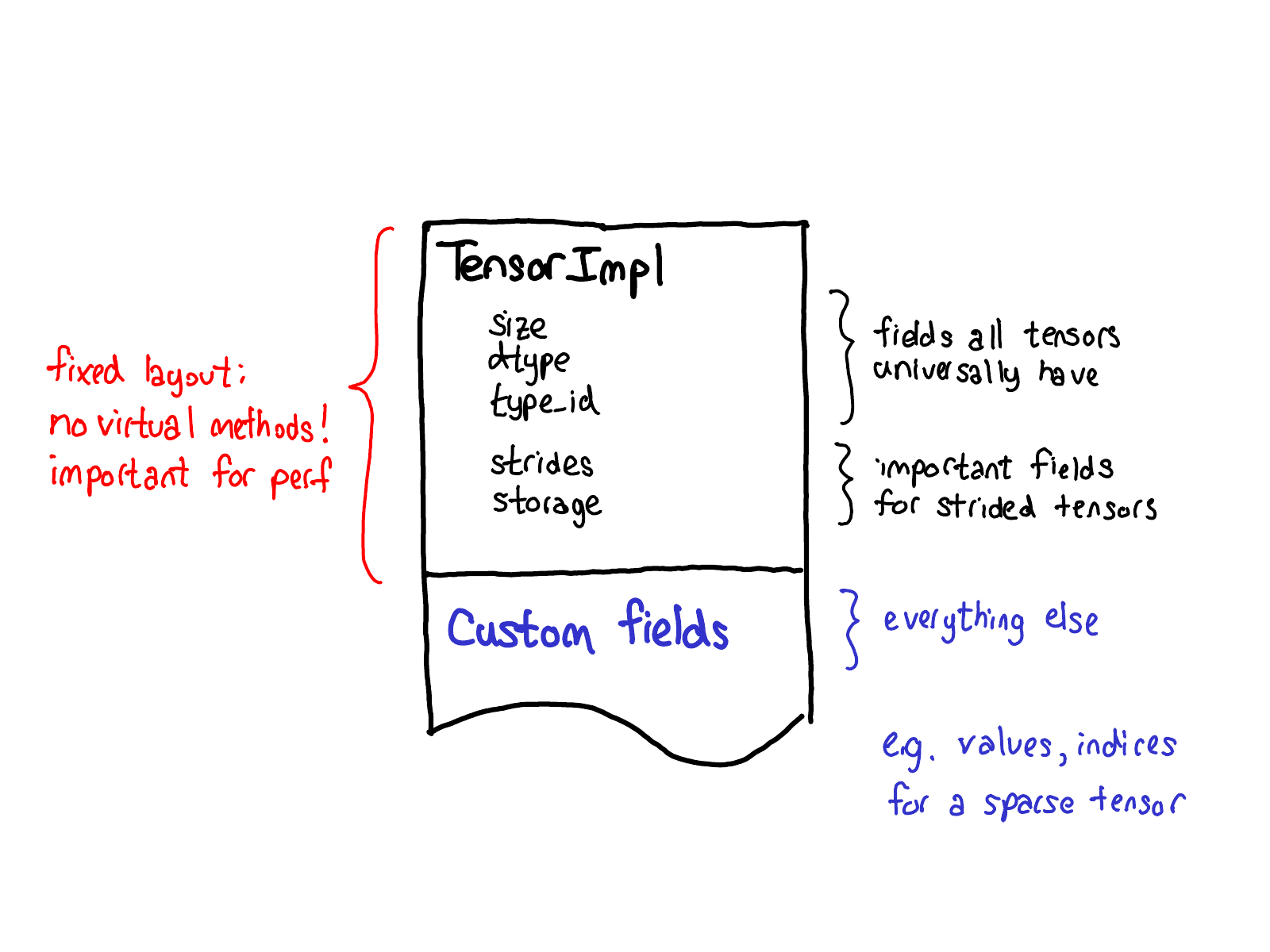
对扩展的看法也影响了张量本身的存储布局。希望张量结构体有固定的布局:不想让诸如“张量的大小是多少?”这样的基本且经常调用的操作需要进行虚函数调用。因此,当你查看张量的实际布局(定义在 TensorImpl 结构体中)时,会看到一个所有认为类似张量的东西都共有的公共前缀字段,再加上一些仅适用于带步长的张量但又非常重要,所以把它们保留在主结构体中的字段,然后是一个可以针对每个张量自定义的后缀字段。例如,稀疏张量就是将索引和值存储在后缀字段中。